Redis is single-threaded. So why is it faster than a multi-threaded database?
I've been building with Supabase and TanStack Query, and I kept running into the same advice: add Redis. I didn't understand why. TanStack Query already caches on the client, and Supabase is fast on its own. Adding a second database just to go faster didn't add up.
Then I read that Redis runs on a single thread and still outperforms databases that use many threads. That contradicted what I assumed, which was that more threads means more speed. So I looked into how it actually works. This is what I found.
What Redis is
Redis is an in-memory key-value store. It keeps all its data in RAM instead of on disk, and you read values by their exact key. It is a database, but because it is so fast, it is most often used as a cache: a layer that holds a copy of data that is expensive to fetch, so you don't recompute it on every request.
The main difference from a database like Postgres is where the data lives:
- Postgres stores data on disk. It is durable and survives restarts, but disk access is slow.
- Redis stores data in RAM. It is much faster to read, but RAM is cleared on restart.
Why in-memory is faster
The speed comes from not touching the disk at all.
RAM is wired close to the CPU and is read in roughly 100 nanoseconds. Disk is separate hardware reached through the I/O system, and it is far slower:
| Storage | Read latency | Relative to RAM |
|---|---|---|
| RAM (Redis) | ~100 nanoseconds | baseline |
| SSD (Postgres) | ~100 microseconds | ~1,000x slower |
| Spinning disk | ~10 milliseconds | ~100,000x slower |
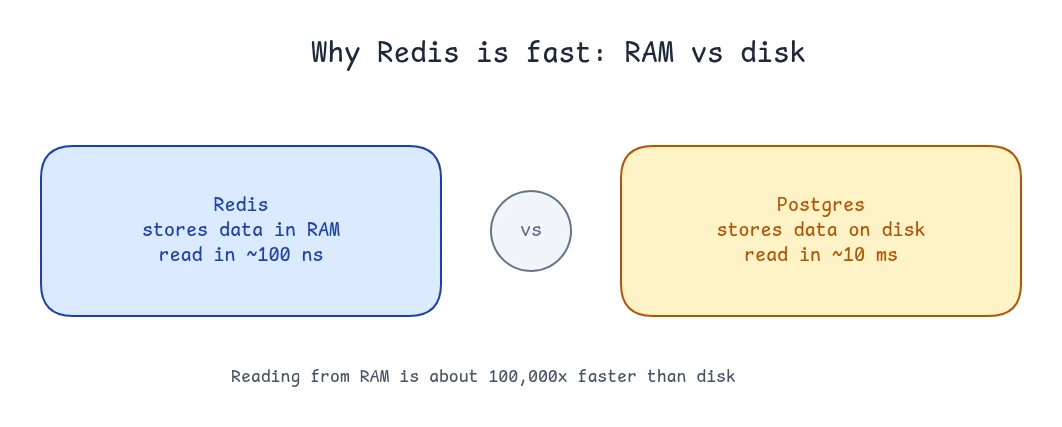
A normal database query has to read from disk. Redis does not, because the data is already in memory. That is the entire reason it is faster.
Losing the cache on restart
Because Redis keeps data in RAM, a restart wipes it. For a cache, that is acceptable. The cached data is only a copy, and the original still lives in Postgres. After a restart, the first request for a given key misses the cache, falls back to Postgres, and the result is written back to Redis. The cache repopulates within seconds.
A cache can be temporary precisely because it is never the source of truth. Redis can also persist to disk through periodic snapshots or an append-only log if you need it to survive restarts, but for pure caching that is usually left off.
The single-threaded part
Redis executes commands on a single thread, one at a time, with no parallelism, and still handles hundreds of thousands of operations per second. Three things make that possible.
1. The data is in memory, so each command takes microseconds. In most databases the bottleneck is waiting on disk, not the CPU. Redis removed the disk, so a single thread is enough to process a very high volume of commands.
2. A single thread has no coordination cost. When multiple threads share data, they need locks to avoid corrupting it. Only one thread can hold a lock at a time, so the others wait. The CPU also spends time switching between threads, saving and restoring each one's state. Locks and context switches are overhead, meaning work that does not serve requests. With one thread, none of it exists.
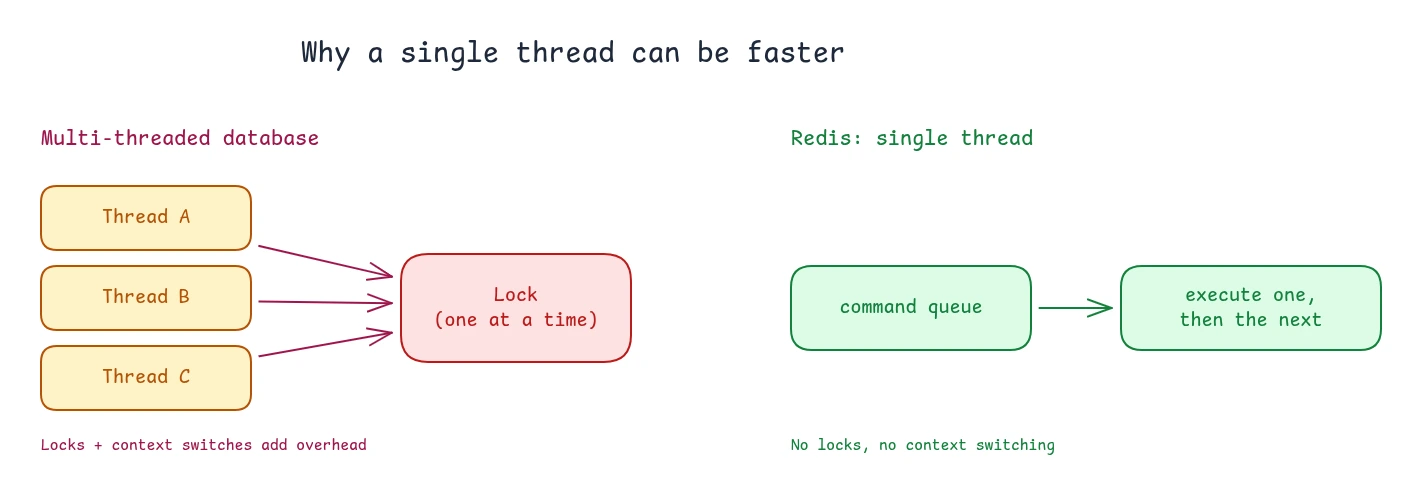
3. It is correct by default. Because commands run one at a time, there are no race conditions. An increment cannot be lost to a concurrent write, and there are no deadlocks.
So single-threading is not a limitation Redis works around. It is part of why it is fast, because it avoids the coordination overhead that slows multi-threaded databases down.
One note for accuracy: Redis 6 added threads for network I/O, but command execution is still single-threaded.
I ran it to check
Claims about speed are easy to repeat, so I ran Redis 8 in a container and pointed redis-benchmark at it: 100,000 requests, 50 parallel clients, against a single Redis instance. These are the numbers from my machine:
$ redis-benchmark -q -t set,get,incr -n 100000 -c 50
SET: 72202.16 requests per second, p50=0.343 msec
GET: 101936.80 requests per second, p50=0.239 msec
INCR: 112359.55 requests per second, p50=0.223 msec
Over 100,000 reads per second, with a median latency under a quarter of a millisecond, all served by one command-executing thread. I checked the thread model from INFO to be sure: io_threads_active:0, and connections are handled with epoll, which is the single-threaded event loop described above.
The exact figure does not matter much, since it depends on hardware and config. What matters is that a single thread reaches six figures of operations per second, because the work per command is tiny and there is no lock contention to pay for.
Where it fits with Supabase and TanStack Query
This was my actual question, so here is the part that cleared it up. TanStack Query and Redis are different kinds of cache, at different layers.
TanStack Query caches in the browser, per user. It stops a single user from refetching the same data as they move around the app. Each user has their own copy.
Redis caches on the server, shared across all users. It stops the database from doing the same work repeatedly for different users.
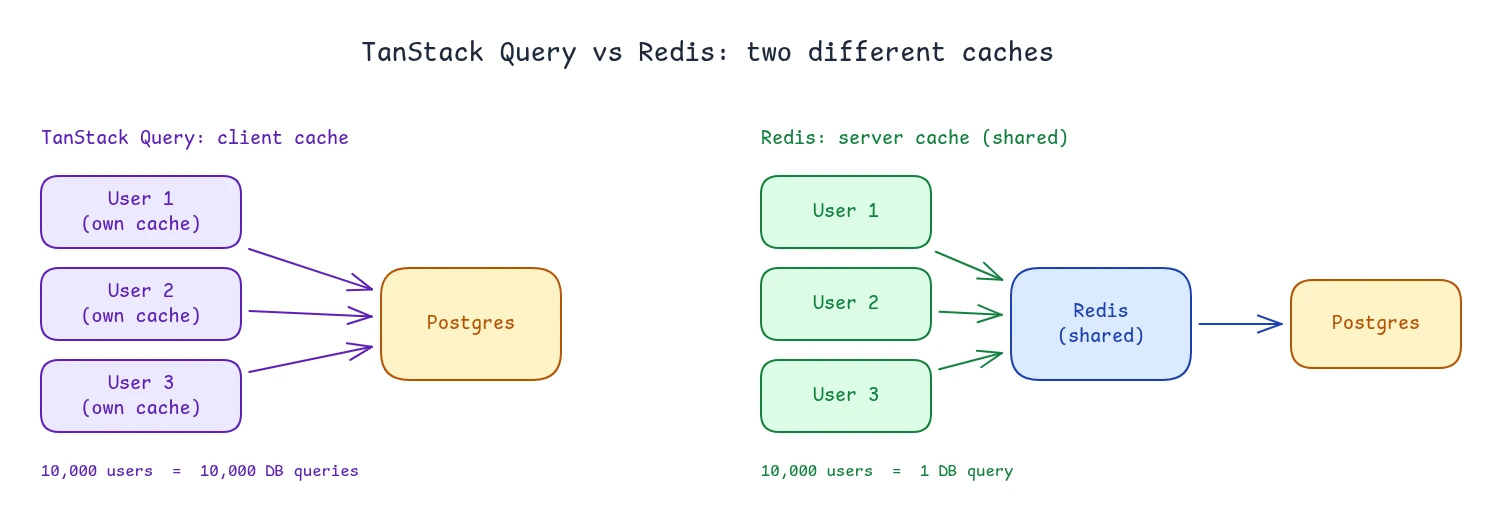
Here is a concrete example. Say 10,000 users load a page that shows the top 10 products.
- With TanStack Query alone, each browser caches the result, but the first load for each user still queries Postgres. That is 10,000 queries.
- With Redis, the first request computes the result and stores it on the server, and the other 9,999 read it from Redis. That is one query.
They solve different problems, and real systems often use both.
When you actually need Redis
If your app talks directly to Supabase from the browser, there is no server in between to run Redis on, and TanStack Query already handles client-side caching. Adding Redis there is complexity you don't need.
Redis is worth adding when you have your own backend and one of these:
- an expensive query that many users request, where caching it once on the server removes repeated database load, or
- shared server state that has to be fast, such as sessions, rate limiting, leaderboards, counters, or queues.
Redis is a fast layer in front of your database, not a replacement for it.
Summary
- Redis is an in-memory key-value store, which is why it is faster than disk-based databases.
- It is single-threaded by design. That avoids the locking and context-switching overhead of multi-threaded databases.
- TanStack Query caches in the browser per user, and Redis caches on the server for everyone. They are not interchangeable.
- Add Redis when many users hit the same expensive query, or when you need shared, fast server state. Not by default.