What happens when you hit Enter on ChatGPT
ChatGPT's answer doesn't appear all at once - it types out, word by word. I always wondered whether that was a real stream or just a front-end animation. So I opened the Network tab and sent one message. It's a real stream, it uses a neat encoding trick, and it's wrapped in more machinery than I expected. Here's the whole thing.
One request carries the entire answer
Filter the Network tab to conversation, send a prompt, and one request stands out immediately:
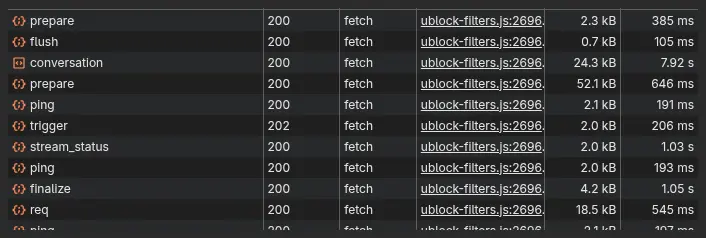
Everything else finishes in milliseconds. The conversation request - a POST to /backend-api/f/conversation - sits open for 7.92 seconds and pulls 24 kB. That long-lived request is the answer being generated and streamed back, live. The model, visible in the request payload, was gpt-5-5.
The answer is Server-Sent Events
Open that request's Response tab and it isn't finished JSON sitting there. It's a stream - the browser's EventStream view fills with a stack of small events as they arrive:
event: delta_encoding
data: "v1"
event: delta
data: {"p": "/message/content/parts/0", "o": "append", "v": "Learning System"}
event: delta
data: {"v": " Design and cracking"}
event: delta
data: {"v": " interviews are related..."}
... dozens more ...
data: [DONE]
This is Server-Sent Events (SSE): one HTTP response the server holds open and keeps writing to over time. Each event: delta is a few freshly-generated tokens. That's the whole reason the text appears to type - you're watching tokens land one chunk at a time, with the page appending each to the message on screen. The stream closes with data: [DONE].
The clever bit: it streams diffs, not text
Look closer at those chunks and there's a small piece of engineering worth admiring. The stream never resends the whole answer. It sends diffs, described as operations on the message object:
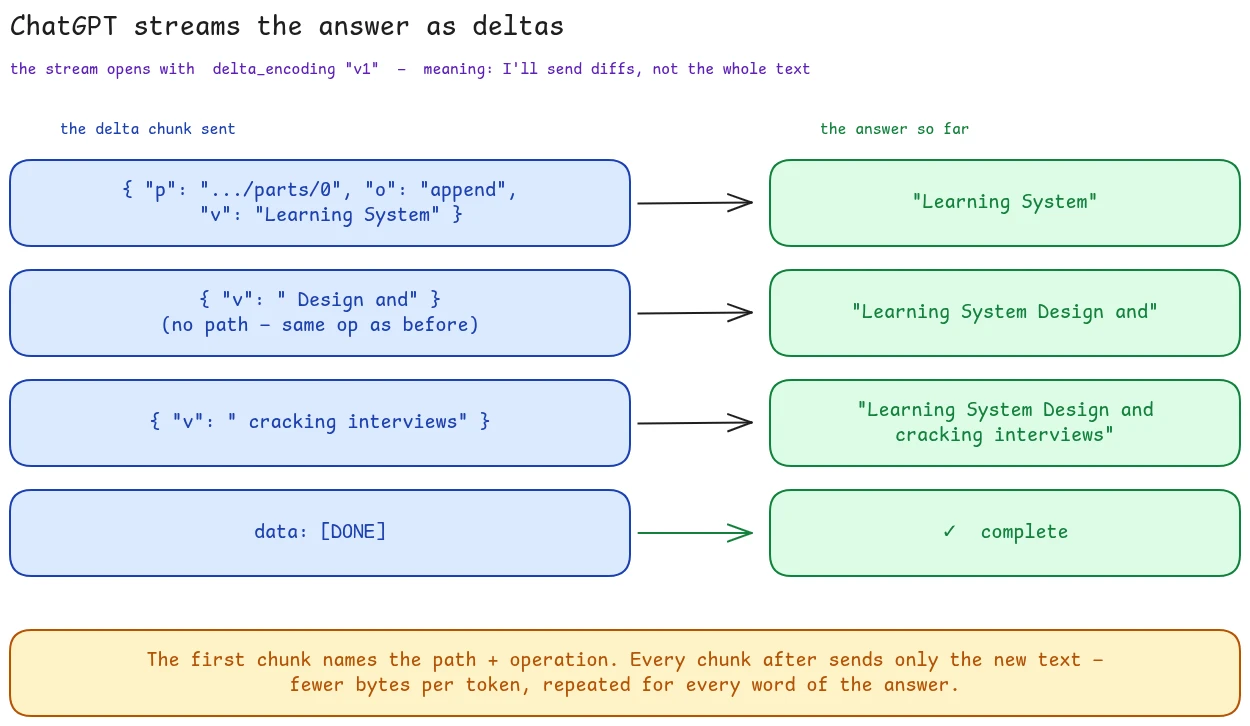
The very first event declares the protocol - delta_encoding: "v1" - and the first real chunk is a full instruction:
{"p": "/message/content/parts/0", "o": "append", "v": "Learning System"}
p is a path (a JSON pointer to the answer's text field), o is the operation (append), and v is the value. But every chunk after that drops the path and the operation entirely:
{"v": " Design and cracking"}
No p, no o - meaning "same operation as last time, here's the next piece." The client just keeps appending each v to the same spot. Multiply that saving across the hundreds of tokens in an answer and it adds up: the protocol spends its bytes on tokens, not on repeating addresses. At the very end, a single patch operation flips the message to finished_successfully.
It starts before you press Send
Here's the part I didn't expect. While your message is still sitting in the box, the page already fires a prepare request carrying your draft text and the model name. The closing metadata of the stream confirms it paid off: conduit_prewarmed: true, warmup_state: "warm". The backend gets warmed on your half-typed message, so the first token returns fast. There's even a separate generate_autocompletions call firing as you type, returning ghost-text suggestions for your own prompt.
One Enter press, a whole orchestra
The streaming answer is the star, but it's surrounded by a surprising cast. Hitting Enter fires more than a dozen requests:
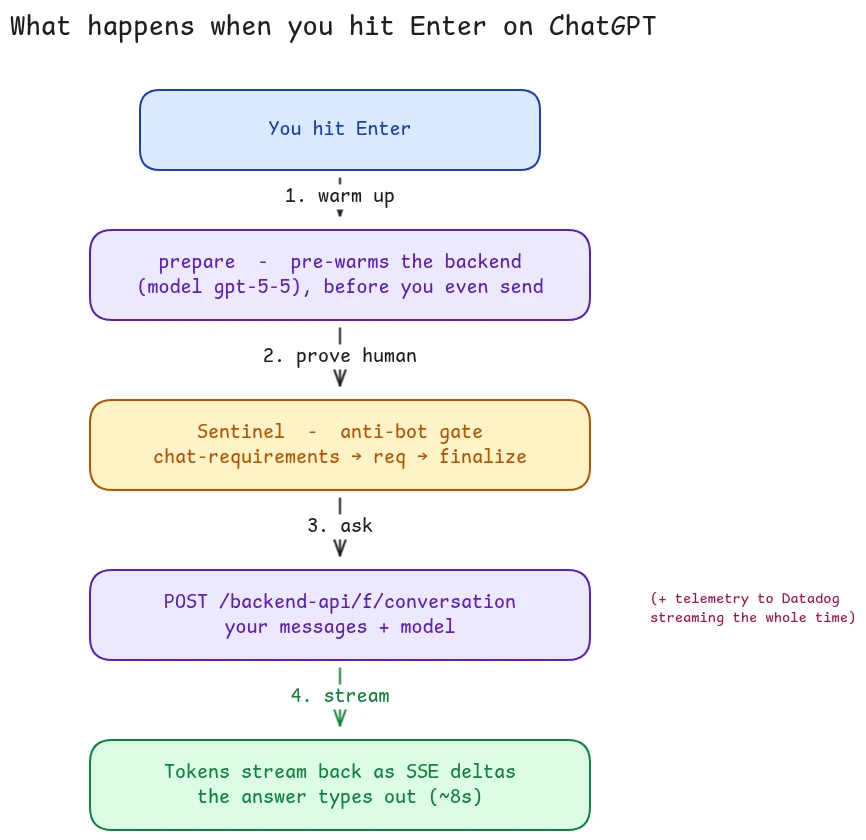
- Pre-warm -
f/conversation/prepare, as above. - An anti-bot gate (Sentinel) - a little dance of
sentinel/chat-requirements/prepare→sentinel/req→sentinel/chat-requirements/finalize, withsentinel/pings throughout. You clear this proof-of-work-style check before you're allowed to generate. This is also why you can't simply script the endpoint from outside - it's gated. - The stream -
POST /f/conversation, the 8-second one. - Side channels -
stream_status,textdocs, latency pings (lat/r), home beacons. - Telemetry - events to
rgstr/flush, plus a browser-logs stream straight to Datadog.
And inside the stream itself, beyond the answer, were three things I didn't expect:
- Hidden context, injected first. Before your text, the stream carries messages the model sees but you don't: a system block, a tool/widget "prefetcher," and a short user-profile note - all flagged
is_visually_hidden_from_conversation: true. - The title, generated mid-answer. A
title_generationevent arrived while the answer was still streaming - and it even revised itself once, swapping in a better title. - A resumable stream. The first event carries a resume token, and the metadata says
resume_with_websockets: true- so if your connection drops, the stream can be picked back up instead of restarting. The whole thing was served fromcluster_region: "centralindia".
The takeaway
A ChatGPT answer is generated token by token, so it's delivered token by token - over one long-lived SSE response, with a diff-based encoding that keeps each token cheap to send. Around that sits exactly the machinery a product at this scale needs: warm the backend early, gate out the bots, stream the result, measure everything.
Want to watch it? Open your own chat, hit F12 → Network → filter conversation, send a message, and read the Response tab. Keep it to your own session, though - the Authorization token and the Sentinel gate are there precisely because this isn't meant to be driven from the outside. Reading along is fair; automating it isn't.